Agentic Realms Dev log - Determining Player Intent
So far I’ve been talking about my game project, Agentic Realms, almost as an afterthought. My first two posts on spec-driven development were experience reports from building out some of Agentic Realms’ first features. In this post and the many that follow, I want to talk about the actual game and developing it.
I want to talk about intent mapping. Before I get to the fancy AI version, let’s talk about where the need comes from.
Intent Parsing
In a MUD (or any text adventure, really) players have to type what they want to do. If they want to move, they have to type go north or north or sometimes they can even get away with n. If they want to attack, it’s kill or attack. Players can manage their loot with take and drop, they can examine individual items within a room or look around in general. These are all pretty common commands.
The traditional way to deal with this is through parsing. We’ll split the player’s input by whitespace and treat the first word as a verb. Then, we’ll match on the verb and dispatch to the right handler. If the verb was go, then we dispatch to handle_move or something like that. The handlers return a boolean that indicates whether the player input was handled successfully. Super easy stuff.
Many years ago, I got this crazy idea that strict verb/noun parsing wasn’t good enough for MUDs. I wanted to see if people could type natural language to achieve the same results. I grabbed an NLP (Natural Language Processing) library and went to work. My idea was to extract the various parts of speech (subject, object, predicate, etc) from player input and then map the parts of speech to in-game actions.
This was a pretty big failure. The technology wasn’t very good (for my purposes) at the time. Running player input through the NLP library took too long, and the overhead cost wasn’t worth the frequently incorrect results.
Nearly two years ago (I can’t believe it’s been that long), I tried another experiment. This time, my plan was to have an LLM take player input and it would then return a data structure representing the player’s intent. Instead of using NLP to extract parts of speech, the LLM would, in theory, convert the player’s freeform text into a JSON structure that contained fields like verb and target and object. So, if a player typed kill spider with sword, the JSON response would be:
{
"verb": "kill",
"target": "spider",
"object": "sword"
}This experiment also failed miserably. Some of the blame lies in the LLM, but I accept my fair share as well. I was writing prompts for the LLM incorrectly. I didn’t really give it the best input possible and so I got very non-deterministic output. Things have changed quite a bit since then.
Intent Mapping with Tools
The way I originally approached the problem a few years ago was to try and prompt the LLM to convert a short input set into a JSON document. I’d set myself up to fail here because that’s a fairly deterministic parsing activity and I was asking the LLM to do it. What I really wanted, was to have the LLM figure out which tool the player wanted to use.
This new perspective actually matches perfectly. These days, when an agent or anything else uses an LLM, the prompt context usually contains a list of tools. These tools are functions that the LLM can “call” in order to provide an answer to the user’s question. The LLMs themselves don’t perform the call, they instead return a well-known data structure representing a tool function call.
Let’s say you’re building an activity planning agent. This agent can take into account the weather forecast for the day of the activity. Since the LLM isn’t going to know the day’s weather, an intermediate response from the LLM represents a call to the weather function. The agent’s internals seamlessly make this call and then the LLM continues processing. This tool call loop continues until the LLM sees no more pending tool uses.
Here’s the fun bit: The list of commands available to a player in a MUD is a list of tools. Taking and dropping items, attacking, examining, moving, casting spells; these are all things that can be invoked as tools. So now instead of me trying to force low-level intent mapping, I can send the player’s input to the LLM along with a list of tools available to the player, and my existing agentic machinery takes care of it all. My tool call handlers are just regular functions that get invoked inside an agent’s callback.
I’m not asking the LLM to parse anything. The player sends text like kill robot and the LLM will attempt to actually perform that function.
In the code below, I’m using a tool function I wrote that creates a structure describing a tool. In this case, it’s the take tool. When I send user text to the LLM with a system prompt that has these tool descriptions in it, the LLM can then ask my code to invoke one of these tools.
tool(
"take",
"Pick up an object that is currently in the player's room and move it into their inventory. Use this when the player wants to acquire, grab, pick up, fetch, take, or otherwise possess an object visible in the current room.",
%{
"type" => "object",
"properties" => %{
"object" => %{
"type" => "string",
"description" =>
"The name of the object to take, as the player referred to it (e.g. 'brass lantern', 'lantern'). Case-insensitive."
}
},
"required" => ["object"]
}
)You can see in this file the code that takes intermediate LLM responses requesting tool use and converts that into tuples, e.g. {:take, object}.
There’s something that feels very elegant about this, and that’s because LLMs determining tool use is something that’s gotten so much attention lately that using a fast model like Haiku on these player inputs works quite well.
For practical purposes, not all players are going to use free form text. Some will still do things like type get lantern. The Agentic Realms code takes this into account. It tries to parse the player intent into a verb and target. If that fails, then it will ask the model to try and call the applicable tool.
Here’s a shot where instead of typing something parseable like drop lantern I used natural language and typed drop the lantern like a bad habit. The instructions the LLM follows to build tool calls easily mapped that to the drop tool with lantern as the argument.
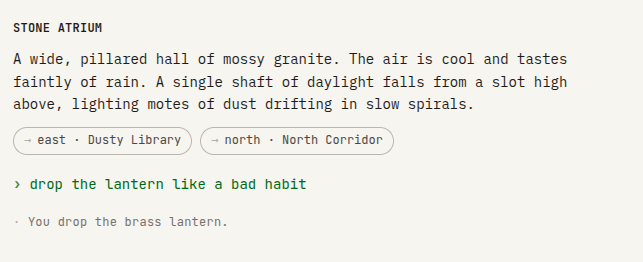
And here’s one where instead of typing get lantern, I typed grab the freakin brass lantern off the floor. In this case, I didn’t even use a verb the game knows how to parse. The parser will try and find a get, and when that fails, the LLM tool call mapper will have figured out to call take(lantern).

Thanks to LLMs and tool call mapping, I’m finally at a point where I’ve started adding modern features onto my aging MUD nostalgia. Soon I’ll write up some posts on how I’m doing things like mapping, inventory, and quests.